以太坊软件源代码免费下载
作者:佚名 来源:91下载站 时间:2023-03-03 15:23
以太坊超级火爆的数字货币交易平台,自己也开发了新的币种,虚拟数字货币在全球掀起,作为最全面的交易平台采用了非常强大的区块链技术打造十分安全可靠,虚拟数字货币集合科技编码等多种模式,很多的开发人员进行开发,对数字货币进行各种加密处理,采用了高科技技术,最重要的是他的源码,下面给大家带来源码解析。
以太坊类list数据结构
以太坊中rlp的具体定义和规则我们可以在黄皮书中找到(Appendix B. Recursive Length Prefix):
序列化定义
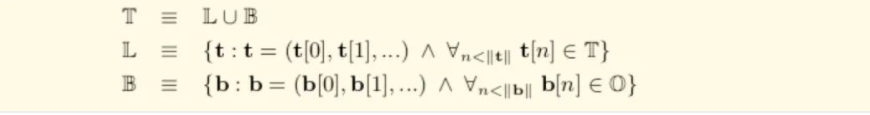
O 所有byte的集合
B 所有可能字节数组
L 不只单一节点的树形结构(比如结构体或者树节点分支节点,非叶子节点)
T 所有字节数组的树形结构组合
序列化处理

通过两个子函数定义RLP分别处理上面说的两种数据类型 Rb(x)字节数组序列化处理规则
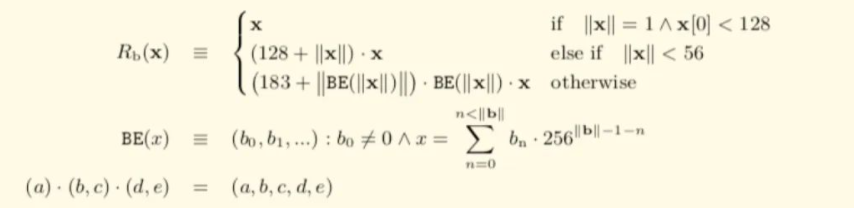
关于大端小端的理解可以参考《理解字节序》比较浅显易懂。关于公式中的一些数学符号的解释:
||x|| 代表了求x的长度
(a).(b,c).(d,e) = (a,b,c,d,e) 代表了concat的操作,也就是字符串的相加操作。"hello "+"world" = "hello world"
BE(x)函数表示去掉了前导0的大端模式。比如4个字节的整形0x1234用大端模式来表示是 00 00 12 34 那么用BE函数处理之后返回的其实是 12 34. 开头的多余的00被去掉了。
^ 符号代表并且的含义。
≡ ,恒等于
Rl(x) 其他类型(树型结构)数据序列化处理规则

如果连接后的字节长度小于56, 那么在连接后的结果前面加上(192 + 连接后的长度),组成最终的结果。比如:["abc", "def"]的编码结果是200 131 97 98 99 131 100 101 102。其中abc的编码为131 97 98 99,def的编码为131 100 101 102。两个子字符串的编码后总长度是8,因此编码结果第一位计算得出:192 + 8 = 200。
如果连接后的字节长度大于等于56, 那么就在连接后的结果前面先加上连接后的长度的大端模式,然后在前面加上(247 + 连接后长度的大端模式的长度)比如: ["The length of this sentence is more than 55 bytes, ","I know it because I pre-designed it"]的编码结果是: 248881798410410132108101110103116104321111023211610410511532115101110116101110991013210511532109111114101321161049711032535332981211161011154432163733210711011111932105116329810199971171151013273321121141014510010111510510311010110032105116,其中前两个字节的计算方式如下:1. 248 = 247 +1; 2. 88 = 86 + 2,在 Rb(x)3示例中,长度为86,而在此例中,由于有两个子字符串,每个子字符串本身的长度的编码各占1字节,因此总共占2字节。第3个字节179依据 Rb(x)规则2得出179 = 128 + 51 第55个字节163同样 Rb(x)2得出163 = 128 + 35
上面是一个递归的定义, 在求取s(x)的过程中又调用了RLP方法,这样使得RLP能够处理递归的数据结构。通过一个复杂的例子来理解一下递归长度前缀:["abc",["The length of this sentence is more than 55 bytes, ","I know it because I pre-designed it"]]编码后的结果:24894131979899248881798410410132108101110103116104321111023211610410511532115101110116101110991013210511532109111114101321161049711032535332981211161011154432163733210711011111932105116329810199971171151013273321121141014510010111510510311010110032105116列表第一项字符串abc依据 Rb(x)规则2,编码结果为131 97 98 99,长度为4。列表第二项也是一个列表项:["The length of this sentence is more than 55 bytes, ","I know it because I pre-designed it"]根据Rl(x)规则2,结果为 248881798410410132108101110103116104321111023211610410511532115101110116101110991013210511532109111114101321161049711032535332981211161011154432163733210711011111932105116329810199971171151013273321121141014510010111510510311010110032105116长度为90,因此,整个列表的编码结果第二位是90 + 4 = 94, 占用1个字节,第一位247 + 1 = 248
标量数据处理

使用RLP处理标量数据,也就是基本的数据,RLP只能够用来处理正整数。 RLP只能处理大端模式处理后的整数。也就是说如果是一个整数x,那么先使用BE(x)函数来把x转换成最简大端模式(去掉了开头的00),然后把BE(x)的结果当成是字节数组来进行编码。
上面就是RLP的编码定义,下面开始我们来看一下以太坊中的实现源码。
代码文件结构
rlp├── decode.go // 解码器├── decode_tail_test.go // 解码示例├── decode_test.go // 解码器测试用例├── doc.go // 文档代码├── encode.go // 编码器├── encode_test.go // 编码器测试用例├── encoder_example_test.go // 编码器示例├── raw.go // 处理编码后rlp数据,比如计算长度、分离、值计数等├── raw_test.go // raw测试用例└── typecache.go // 类型缓存,记录数据类型->编码器|解码器的映射
可以直接从示例 encoderexampletest.go 中来看,这个示例中实现了一个如何通过rlp编码struct的调用:
type MyCoolType struct { Name string a, b uint}func (x *MyCoolType) EncodeRLP(w io.Writer) (err error) { if x == nil { // 结构体为空指针,编码{0, 0} err = Encode(w, []uint{0, 0}) } else { // 编码指定的值 err = Encode(w, []uint{x.a, x.b}) } return err}func ExampleEncoder() { var t *MyCoolType bytes, _ := EncodeToBytes(t) // t MyCoolType为nil编码为字节数组 fmt.Printf("%v → %X\n", t, bytes) t = &MyCoolType{Name: "foobar", a: 5, b: 6} bytes, _ = EncodeToBytes(t) // t 为struct fmt.Printf("%v → %X\n", t, bytes) // Output: // → C28080 // &{foobar 5 6} → C20506}
通过上面的测试用例代码,可以看到 EncodeToBytes就是编码的函数,往下走,看一下编码器具体实现 encode.go:
var ( EmptyString = []byte{0x80} EmptyList = []byte{0xC0})// Encoder is implemented by types that require custom// encoding rules or want to encode private fields.type Encoder interface { // EncodeRLP should write the RLP encoding of its receiver to w. // If the implementation is a pointer method, it may also be // called for nil pointers. // // Implementations should generate valid RLP. The data written is // not verified at the moment, but a future version might. It is // recommended to write only a single value but writing multiple // values or no value at all is also permitted. EncodeRLP(io.Writer) error}
首先定义了空字符串和空列表的值,定义了 Encoder接口,我们可以看到上面的MyCoolType就实现了该接口的EncodeRLP方法,继续往下看EncodeToBytes的具体实现:
// EncodeToBytes 返回RLP编码后的值.func EncodeToBytes(val interface{}) ([]byte, error) { eb := encbufPool.Get().(*encbuf) // 从encbufPool池中获取encbuf实例 defer encbufPool.Put(eb) // 调用结束以后重新放入池中 eb.reset() // 初始化encbuf if err := eb.encode(val); err != nil { // 对数据编码 return nil, err } return eb.toBytes(), nil //将编码后的数据和头部拼接成byte[]后返回}
encbufPool是一个sync.Pool,可以通过一个资源池来提高编码效率,减少资源浪费。来看下encbuf的结构定义:
type encbuf struct { str []byte // 包含了除了列表的头部的所有的编码的内容 lheads []*listhead // 所有的列表头 lhsize int // lheads的长度 sizebuf []byte // 9个字节大小的辅助buffer,用来处理uint的编码}type listhead struct { offset int // 记录了列表数据在str字段的起始位置 size int // 编码数据的总长度 (包括列表头)}
encbuf看起来是在编码过程的一个buffer的作用,其定义了一些encode过程中的操作方法,具体每个函数的实现不做代码分析了,这里大略说一下每个函数的作用:
encode(valinterface{})error 编码函数
(w*encbuf)encodeString(b[]byte) 将编码后的原始数据连接到已编码内容之后
encodeStringHeader(sizeint) 将头部结构体中新编码后的元素和之前已经编码的内容连接
list()*listhead 保存每个元素编码后的头部lheads信息
listEnd(lh*listhead) 编码连接后的长度lhsize统计
reset() encbuf 初始化
size()int 计算编码后内容和头部长度之和
toBytes()[]byte 将每个头部lheads连接到对应的编码数据后
toWriter(outio.Writer)(err error) 通过io流将编码后头部写到编码后,
Write(b[]byte)(int,error) 实现io.Writer接口,以便于可以传入EncodeRLP
继续上面的EncodeToBytes函数,我来看一下 eb.encode(val)编码函数具体做了什么:
func (w *encbuf) encode(val interface{}) error { rval := reflect.ValueOf(val) ti, err := cachedTypeInfo(rval.Type(), tags{}) if err != nil { return err } return ti.writer(rval, w)}
首先通过reflect反射机制获取编码值的类型,后和tags一起传入 cachedTypeInfo,往下看cachedTypeInfo做了什么typecache.go:
var ( typeCacheMutex sync.RWMutex // 读写锁 typeCache = make(map[typekey]*typeinfo)// 类型->编码|解码函数的映射,不同的数据类型对应不同的编码和解码方法)type typeinfo struct { decoder // 解码 writer // 编码}type tags struct { nilOK bool // 是否为空值 tail bool // 该字段是否含其他列表元素。它只能设置为最后一个字段,该字段必须是切片类型。 ignored bool // 是否忽略}type typekey struct { reflect.Type // 数据类型 tags // 根据tags可能会生成不同的解码器。}type decoder func(*Stream, reflect.Value) errortype writer func(reflect.Value, *encbuf) errorfunc cachedTypeInfo(typ reflect.Type, tags tags) (*typeinfo, error) { typeCacheMutex.RLock() // 加读锁 info := typeCache[typekey{typ, tags}] // 从缓存中获取编码解码器 typeCacheMutex.RUnlock() if info != nil { return info, nil } // 缓存中没有时通过type和tags生成编码解码器 typeCacheMutex.Lock() defer typeCacheMutex.Unlock() return cachedTypeInfo1(typ, tags)}
cachedTypeInfo函数主要是从缓存中来根据数据类型来获取编码解码器,如果不存在时就通过 cachedTypeInfo1 来创建一个对应类型的编码解码器,这里需要注意的typeCacheMutex 进程锁来避免多线程资源保护和互斥,下面继续看下 cachedTypeInfo1如何根据typekey来创建typeinfo的:
func cachedTypeInfo1(typ reflect.Type, tags tags) (*typeinfo, error) { key := typekey{typ, tags} info := typeCache[key] if info != nil { // 另外一个协程首先获得锁,再次验证避免多进程并发请求 return info, nil } typeCache[key] = new(typeinfo) info, err := genTypeInfo(typ, tags) if err != nil { // 生成失败清除空间 delete(typeCache, key) return nil, err } *typeCache[key] = *info return typeCache[key], err}
该函数并不是实际创建缓存的函数,其中调用了 genTypeInfo函数,顺着往下看:
func genTypeInfo(typ reflect.Type, tags tags) (info *typeinfo, err error) { info = new(typeinfo) if info.decoder, err = makeDecoder(typ, tags); err != nil { return nil, err } if info.writer, err = makeWriter(typ, tags); err != nil { return nil, err } return info, nil}
显而易见,这里分别调用 makeDecoder和 makeWriter来创建解码和编码,我们来看下编码器的实现encode.go:
// 通过类型和tags创建对应的具体编码函数func makeWriter(typ reflect.Type, ts tags) (writer, error) { kind := typ.Kind() switch { case typ == rawValueType: return writeRawValue, nil case typ.Implements(encoderInterface): return writeEncoder, nil case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(encoderInterface): return writeEncoderNoPtr, nil case kind == reflect.Interface: return writeInterface, nil case typ.AssignableTo(reflect.PtrTo(bigInt)): return writeBigIntPtr, nil case typ.AssignableTo(bigInt): return writeBigIntNoPtr, nil case isUint(kind): return writeUint, nil case kind == reflect.Bool: return writeBool, nil case kind == reflect.String: return writeString, nil case kind == reflect.Slice && isByte(typ.Elem()): return writeBytes, nil case kind == reflect.Array && isByte(typ.Elem()): return writeByteArray, nil case kind == reflect.Slice || kind == reflect.Array: return makeSliceWriter(typ, ts) case kind == reflect.Struct: return makeStructWriter(typ) case kind == reflect.Ptr: return makePtrWriter(typ) default: return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ) }}
这个函数很简单,通过type来设置对应的具体编码器,注意一下ts也就是tags参数,只有类型为slice和array时候才会用到,具体每个类型对应的编码器实现就不一一分析了,很值得每一个源码看一下,加深一下对上面黄皮书定义的规则的理解。对于结构体的编码在黄皮书中并没有公式定义,我们来看下源码了解一下:
type field struct { index int info *typeinfo}func makeStructWriter(typ reflect.Type) (writer, error) { fields, err := structFields(typ) // 通过typ.NumField反射机制来解析struct结构,并获取每个字段的解码器 if err != nil { return nil, err } writer := func(val reflect.Value, w *encbuf) error { lh := w.list() for _, f := range fields { //f是field结构, f.info是typeinfo的指针, 所以f.info.writer就是调用字段的编码器方法 if err := f.info.writer(val.Field(f.index), w); err != nil { return err } } w.listEnd(lh) return nil } return writer, nil}
structFields 方法中通过reflect.Type的NumField获取其Field,然后调用cachedTypeInfo1来获取每个Field的编码器,所以这是一个递归的调用。最后遍历Field的数组fields,调用f.info.writer具体的编码器来编码。我们继续回到encoderexampletest.go来看下示例中
var t *MyCoolType bytes, _ := EncodeToBytes(t)
这里的t是MyCoolType的一个指针,MyCoolType实现了EncodeRLP的接口,根据 makeWriter中的case找到 typ.Implements(encoderInterface)分支,调用了 writeEncoder:
func writeEncoder(val reflect.Value, w *encbuf) error { return val.Interface().(Encoder).EncodeRLP(w)}
这里直接调用了 EncodeRLP(w)接口方法,从上面的示例代码中看,那么就是调用 Encode(w,[]uint{0,0}),我们上面分析过了,encbuf实现了io.Writer接口的Writer方法,这里的w就是encbuf:
func Encode(w io.Writer, val interface{}) error { if outer, ok := w.(*encbuf); ok { // 如果是*encbuf类型,则直接返回outer.encode return outer.encode(val) } eb := encbufPool.Get().(*encbuf) defer encbufPool.Put(eb) eb.reset() if err := eb.encode(val); err != nil { return err } w是io.Writer,eb.toWriter(w)流 return eb.toWriter(w)}
- 上一篇:阴阳师修罗鬼童丸斗技怎么玩?两套阵容教你玩SP鬼童丸斗技
- 下一篇:没有
最新资讯
更多+大家都在用
-
 美少女养成计划下载美少女养成计划下载
美少女养成计划下载美少女养成计划下载 -
 少女都市3D中文版游戏少女都市3D中文版游戏
少女都市3D中文版游戏少女都市3D中文版游戏 -
 抖音外婆的小农院 v1.0.7官方版抖音外婆的小农院 v1.0.7官方版
抖音外婆的小农院 v1.0.7官方版抖音外婆的小农院 v1.0.7官方版 -
 花花姑娘之美妆奇缘最新版花花姑娘之美妆奇缘最新版
花花姑娘之美妆奇缘最新版花花姑娘之美妆奇缘最新版 -
 健康兴安app红色兴安 v1.1.20210303133健康兴安app红色兴安 v1.1.20210303133
健康兴安app红色兴安 v1.1.20210303133健康兴安app红色兴安 v1.1.20210303133 -
 狂暴西游记bt版狂暴西游记bt版
狂暴西游记bt版狂暴西游记bt版 -
 舞泡最新安卓版 官方版2.5.1舞泡最新安卓版 官方版2.5.1
舞泡最新安卓版 官方版2.5.1舞泡最新安卓版 官方版2.5.1 -
 奇妙星际宇航员游戏奇妙星际宇航员游戏
奇妙星际宇航员游戏奇妙星际宇航员游戏 -
 保卫萝卜2破解版手游下载保卫萝卜2破解版手游下载
保卫萝卜2破解版手游下载保卫萝卜2破解版手游下载 -
 我要成为包租婆游戏我要成为包租婆游戏
我要成为包租婆游戏我要成为包租婆游戏 -
 九州梦境最新版下载九州梦境最新版下载
九州梦境最新版下载九州梦境最新版下载 -
 王者争雄手游最新免费版王者争雄手游最新免费版
王者争雄手游最新免费版王者争雄手游最新免费版 -
 懒人听书破解版软件懒人听书破解版软件
懒人听书破解版软件懒人听书破解版软件 -
 免耽漫画观看无删减版app免耽漫画观看无删减版app
免耽漫画观看无删减版app免耽漫画观看无删减版app -
 神武3手游最新版神武3手游最新版
神武3手游最新版神武3手游最新版 -
 黑豹vp加速器黑豹vp加速器
黑豹vp加速器黑豹vp加速器
推荐游戏
-
 死胡同之王安卓汉化整合版下载 死胡同死胡同之王安卓汉化整合版下载 死胡同
死胡同之王安卓汉化整合版下载 死胡同死胡同之王安卓汉化整合版下载 死胡同 -
 萌妖出没中文破解版手游下载 萌妖出没萌妖出没中文破解版手游下载 萌妖出没
萌妖出没中文破解版手游下载 萌妖出没萌妖出没中文破解版手游下载 萌妖出没 -
 古代人生安卓破解版下载-古代人生最新古代人生安卓破解版下载-古代人生最新
古代人生安卓破解版下载-古代人生最新古代人生安卓破解版下载-古代人生最新 -
 网吧模拟器内置作弊菜单mod下载修改版_网吧模拟器内置作弊菜单mod下载修改版_
网吧模拟器内置作弊菜单mod下载修改版_网吧模拟器内置作弊菜单mod下载修改版_ -
 极限竞速3D最新版安卓下载_极限竞速3D极限竞速3D最新版安卓下载_极限竞速3D
极限竞速3D最新版安卓下载_极限竞速3D极限竞速3D最新版安卓下载_极限竞速3D -
 赛车经验中文版下载-赛车经验最新版下赛车经验中文版下载-赛车经验最新版下
赛车经验中文版下载-赛车经验最新版下赛车经验中文版下载-赛车经验最新版下 -
 顺玩烈焰传奇安卓版下载-顺玩烈焰传奇顺玩烈焰传奇安卓版下载-顺玩烈焰传奇
顺玩烈焰传奇安卓版下载-顺玩烈焰传奇顺玩烈焰传奇安卓版下载-顺玩烈焰传奇 -
 手游真实摩托竞赛3D无限金币版下载 真手游真实摩托竞赛3D无限金币版下载 真
手游真实摩托竞赛3D无限金币版下载 真手游真实摩托竞赛3D无限金币版下载 真 -
 节奏大师无限体力破解版下载-节奏大师节奏大师无限体力破解版下载-节奏大师
节奏大师无限体力破解版下载-节奏大师节奏大师无限体力破解版下载-节奏大师
推荐软件
-
 防伪相机最新版下载-防伪相机app1.0.0防伪相机最新版下载-防伪相机app1.0.0
防伪相机最新版下载-防伪相机app1.0.0防伪相机最新版下载-防伪相机app1.0.0 -
 国珍在线app最新版下载-国珍在线官方版国珍在线app最新版下载-国珍在线官方版
国珍在线app最新版下载-国珍在线官方版国珍在线app最新版下载-国珍在线官方版 -
 coinw币赢官方最新版下载_coinw币赢手coinw币赢官方最新版下载_coinw币赢手
coinw币赢官方最新版下载_coinw币赢手coinw币赢官方最新版下载_coinw币赢手 -
 运满满司机版注册下载-运满满司机版下运满满司机版注册下载-运满满司机版下
运满满司机版注册下载-运满满司机版下运满满司机版注册下载-运满满司机版下 -
 麻雀记手机版下载-麻雀记app下载v4.7.8麻雀记手机版下载-麻雀记app下载v4.7.8
麻雀记手机版下载-麻雀记app下载v4.7.8麻雀记手机版下载-麻雀记app下载v4.7.8 -
 7乐安卓app下载-7乐appv3.2.3官方版下7乐安卓app下载-7乐appv3.2.3官方版下
7乐安卓app下载-7乐appv3.2.3官方版下7乐安卓app下载-7乐appv3.2.3官方版下 -
 菜鸟裹裹app官方版下载-菜鸟裹裹app安菜鸟裹裹app官方版下载-菜鸟裹裹app安
菜鸟裹裹app官方版下载-菜鸟裹裹app安菜鸟裹裹app官方版下载-菜鸟裹裹app安 -
 网上国网app最新版下载-网上国网app安网上国网app最新版下载-网上国网app安
网上国网app最新版下载-网上国网app安网上国网app最新版下载-网上国网app安 -
 抖音网页版登录入口下载-抖音网络版登抖音网页版登录入口下载-抖音网络版登
抖音网页版登录入口下载-抖音网络版登抖音网页版登录入口下载-抖音网络版登